[ML – 22] Convolution Neural Network : AlexNet
Chào các bạn, hôm nay chúng ta sẽ cùng nhau tìm hiểu về mô hình AlexNet - mô hình đầu tiên cho thấy sức mạnh của CNN.
Origin Paper:
Đây là mô hình được phát triển bởi Alex Krizhevsky, Ilya Sutskever và Geoffrey E. Hinton (được mệnh danh là God father của Deep Learning)
1. Introduction:
Vào năm 2012, AlexNet được coi là mô hình cho kết quả tốt nhất trong việc phân loại ảnh - cụ thể trong bài báo này viết về kết quả thu được trên tập dữ liệu con của ImageNet (phân loại 1000 class với 1.2 triệu tấm ảnh chất lượng cao). Kết quả thu được như sau: (trên tập test) Top 1 error: 37.5 % Top 5 error: 17.0 % Mô hình này có tới 60 triệu tham số (để học) và khoảng 650.000 neurons. Trong đó bao gồm 5 lớp convolution, 3 lớp fully-connected và cuối cùng là softmax với 1000 output.
2. Data set:
ImageNet là tập dữ liệu với 15 triệu bức ảnh đã được gán nhãn với khoảng 22000 class. Kể từ năm 2010, một phần thi trong cuộc thi Pascal Visual Object Challenge, được tổ chức hàng năm với tên gọi ImageNet Large-Scale Visual Recognition Challenge (ILSVRC). ILSVRC sử dụng một phần của tập ImageNet với khoảng 1.2 triệu bức ảnh training (training set), 50.000 bức ảnh validation (validation set) và 150000 bức ảnh testing (test set) Mô hình sử dụng input có kích thước cố định 256 x 256, trong khi ImageNet có kích thước các bức ảnh không cố định, vì vậy nên các bức ảnh được preprocessing bằng cách scale các tấm ảnh về kích thước: cạnh bé hơn của tấm ảnh được scale về 256, cạnh còn lại được scale về cùng tỉ lệ. Sau đó crop tấm ảnh tại center để ra được kích thước 256 x 256. Cuối cùng là tại mỗi giá trị RGB của một điểm ảnh, ta trừ đi mean của tất cả các pixel trong training set.
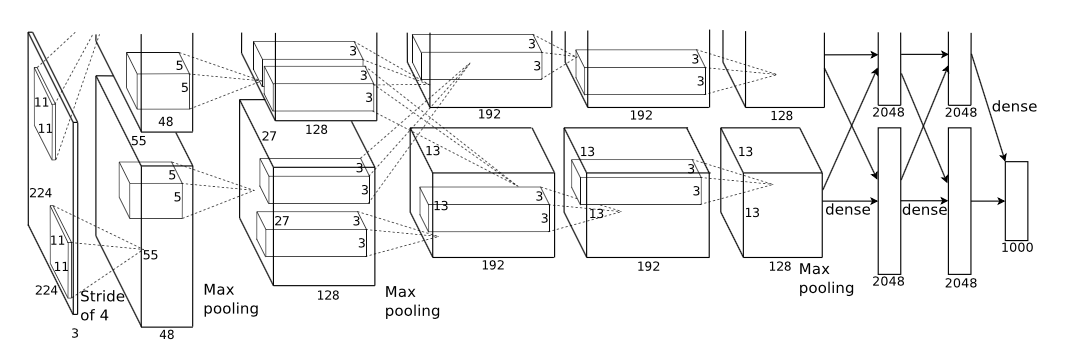
3. The architecture
-
Input Layer: 224 x 224 x 3
-
Conv2dBlock 1:
Filters: 96 filter with size 11 x 11 x 3 (stride = 4, zero_padding = VALID)
Feature Map: 55 x 55 x 96
GPU1: 55 x 55 x 48
GPU2: 55 x 55 x 48
ReLU:
GPU1: 55 x 55 x 48
GPU2: 55 x 55 x 48
LRN: (Local Response Normalized)
GPU1: 55 x 55 x 48
GPU2: 55 x 55 x 48
Overlap max pooling:
GPU1: 27 x 27 x 48
GPU2: 27 x 27 x 48 -
Conv2dBlock 2:
Filters: 256 filter with size 5 x 5 x 48 (stride = 1, zero_padding = SAME)
Feature Map: 27 x 27 x 256
GPU1: 27 x 27 x 128
GPU2: 27 x 27 x 128
ReLU:
GPU1: 27 x 27 x 128
GPU2: 27 x 27 x 128
LRN:
GPU1: 27 x 27 x 128
GPU2: 27 x 27 x 128
Overlap max pooling:
GPU1: 13 x 13 x 128
GPU2: 13 x 13 x 128\ -
Conv2dBlock 3:
Filters: 384 filter with size 3 x 3 x 256 (stride = 1, zero_padding = SAME)
Feature Map: 13 x 13 x 384
GPU1: 13 x 13 x 192
GPU2: 13 x 13 x 192
ReLU:
GPU1: 13 x 13 x 192
GPU2: 13 x 13 x 192\ -
Conv2dBlock 4:
Filters: 384 filter with size 3 x 3 x 192 (stride = 1, zero_padding = SAME)
Feature Map: 13 x 13 x 384
GPU1: 13 x 13 x 192
GPU2: 13 x 13 x 192
ReLU:
GPU1: 13 x 13 x 192
GPU2: 13 x 13 x 192\ -
Conv2dBlock 5:
Filters: 256 filter with size 3 x 3 x 192
Feature Map: 13 x 13 x 256
GPU1: 13 x 13 x 128
GPU2: 13 x 13 x 128
ReLU:
GPU1: 13 x 13 x 128
GPU2: 13 x 13 x 128
LRN:
GPU1: 13 x 13 x 128
GPU2: 13 x 13 x 128
Overlap max pooling:
GPU1: 6 x 6 x 128
GPU2: 6 x 6 x 128\ -
FC1: 2048 x 2 = 4096
GPU1: 2048
GPU2: 2048\ -
FC2: 2048 x 2 = 4096
GPU1: 2048
GPU2: 2048\ -
Output Layer: 1000
4. Highlight:
i. ReLU
Như các bạn đã thấy trong kiến trúc của AlexNet, thay vì dùng các hàm activation như sigmoid hay tanh, AlexNet đã bắt đầu sử dụng hàm ReLU nhằm giúp tăng tốc độ training (tránh được vanishing gradient) và tránh phải rủi ro tràn số (tanh và sigmoid đều sử dụng \(e^x\) nên dễ bị xấp xỉ = 0 hoặc tràn số khi \(x\) quá lớn hoặc quá nhỏ).
ii. GPU
Do vấn đề về giới hạn bộ nhớ của GPU nên với một GPU độ phức tạp của mạng sẽ bị giới hạn. Nên để AlexNet với kiến trúc như trên thì cần tới 2 GPU để train. Các phần mạng được train trên các GPU khác nhau cũng sẽ chỉ giao tiếp với nhau ở một số lớp nhất định (như trên hình và giải thích trong phần kiến trúc mạng).
iii. LRN (Local Response Normalization)
Để ý rằng với mỗi filter khi áp vào input cho kết quả là 1 channel của output, và các channel này không có mối ràng buộc mất thiết nào với nhau (ngoại trừ việc chung input trước khi tính tích chập) hay thứ tự của các channel trên output là không quan trọng (khi chưa xét đến các layer tiếp theo). Trong trường hợp của AlexNet, sau khi qua activation ReLU, mỗi neuron sau khi tính tích chập được normalize dựa trên những neuron lân cận nó (lân cận ở đây là cùng vị trí trên trục channel chứ không phải width hay height). Cụ thể công thức normalize như sau:
\[b ^{i} _{x,y} = \frac{a ^{i} _{x,y}}{(k + \alpha \sum^{min(N-1,i+\frac{n}{2})}_{j=max(0,i-\frac{n}{2})} (a^{i}_{x,y})^{2})^{\beta}}\]Trong đó:
n: số output lân cận - đây là một hyper param
N: số lượng filter của layer này
\( a^i_{x,y} \): là neuron output ở vị trí \((x,y)\) sau khi áp filter thứ \(i\)
\(k, \alpha, \beta\): là các hyper param để điều chỉnh quá trình normalize này.
Trong paper có nhắc tới việc lựa chọn các hyper param này lần lượt là \(k=2, n=5, \alpha = 10^{-4}, \beta = 0.75 \) giúp cải thiện 1-2% error.
iiii. Overlapping Pooling
Pooling layer của CNN được định nghĩa bởi window size và tốc độ stride. Trong trường hợp window size = stride, các output của các window sẽ độc lập lẫn nhau, khi đó pooling mang ý nghĩa của việc giảm chiều dữ liệu là chính. Nhưng khi window size > stride, các output của các window sẽ có ràng buộc lẫn nhau bởi các window bị overlap. Việc này giúp cho model tránh được phần nào overfitting, trong bài báo có viết, việc sử dựng window size = 3 và stride = 2 giúp cải thiện sai số khoảng 0.3% - 0.4% khi so với việc sử dụng window size = 2 và stride = 2.
5. Summary:
AlexNet được biết đến như bước đầu thành công rực rỡ của CNN trong thập kỷ này. Sự xuất hiện của các GPU mạnh mẽ, hàm activation ReLU cũng như các phương pháp normalize mới cho các layer của mạng neuron giúp Deep Learning có được bước tiến đáng kể trong những năm qua. Còn khá nhiều điều hay ho mà các tác giả viết trong paper về AlexNet, tôi khuyên các bạn nên xem thử bài báo này để hiểu tường tận những gì mà AlexNet đã đạt được.